Behind RoboFinals: NVIDIA Isaac Lab – Arena
and Lightwheel BenchHub
Robotics foundation models have rapidly outgrown existing academic benchmarks. While model capabilities continue to scale, real-world evaluation remains slow, expensive, and difficult to reproduce across teams, robots, and environments. As a result, the field lacks a shared, systematic way to measure progress, compare approaches, and stress-test models under realistic conditions.
To address this gap, Lightwheel introduces RoboFinals, an industry-grade simulation evaluation platform designed to rigorously evaluate robotics foundation models across complex tasks, environments, and robot embodiments. RoboFinals is already adopted by leading foundation-model teams, including Qwen, and is being refined through close collaboration with teams actively training and deploying frontier embodied models. This tight feedback loop between large-scale evaluation and real-world deployment ensures RoboFinals measures capabilities that matter in practice, with the long-term goal of becoming a reference evaluation layer for embodied AI.
Achieving this level of evaluation requires more than simulation alone. RoboFinals is built on two tightly integrated pieces of infrastructure: NVIDIA Isaac Lab – Arena, co-developed by Lightwheel and Nvidia, and Lightwheel BenchHub, our benchmark orchestration and execution framework.
Example of RoboFinals-100 Benchmark
Why Evaluation Now?
The urgency around evaluation is not accidental—it is a direct consequence of how robotics foundation models are evolving. As models scale, training loss and isolated demos are no longer reliable indicators of real capability. Small architectural or data changes can produce impressive demonstrations while masking brittleness, poor generalization, or failure under distribution shift.
At the same time, the field is moving from narrow, task-specific systems toward foundation models expected to operate across tasks, environments, and robot embodiments. This shift fundamentally raises the bar for evaluation: benchmarks must stress long-horizon reasoning, physical interaction, failure recovery, and embodiment generalization—not just short scripted successes.
Without rigorous, scalable evaluation, the community risks optimizing for surface-level improvements rather than underlying capability. Evaluation is therefore no longer a downstream validation step—it has become a central mechanism for guiding data collection, model design, and learning itself.
This shift makes evaluation infrastructure—not just models or data—the critical bottleneck, motivating the development of NVIDIA Isaac Lab – Arena as a shared, scalable foundation for embodied AI evaluation.
NVIDIA Isaac Lab – Arena: open-source evaluation framework co-developed by Lightwheel and NVIDIA
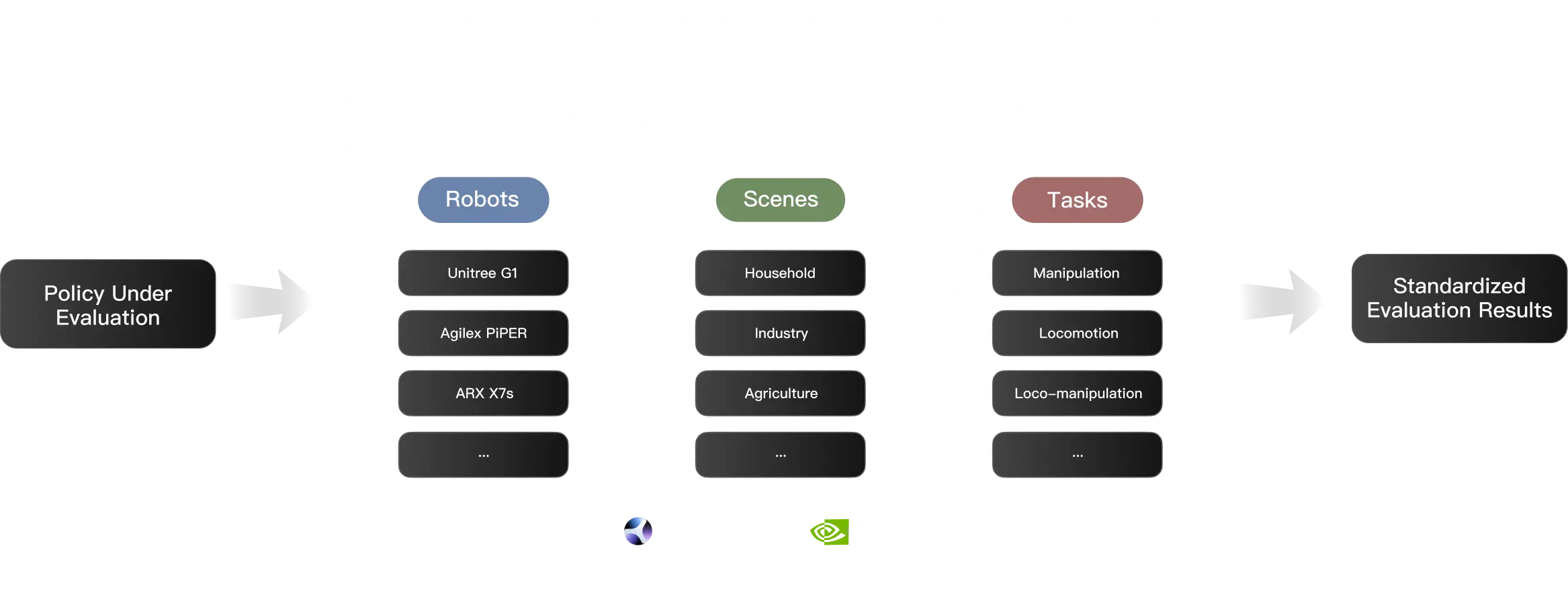
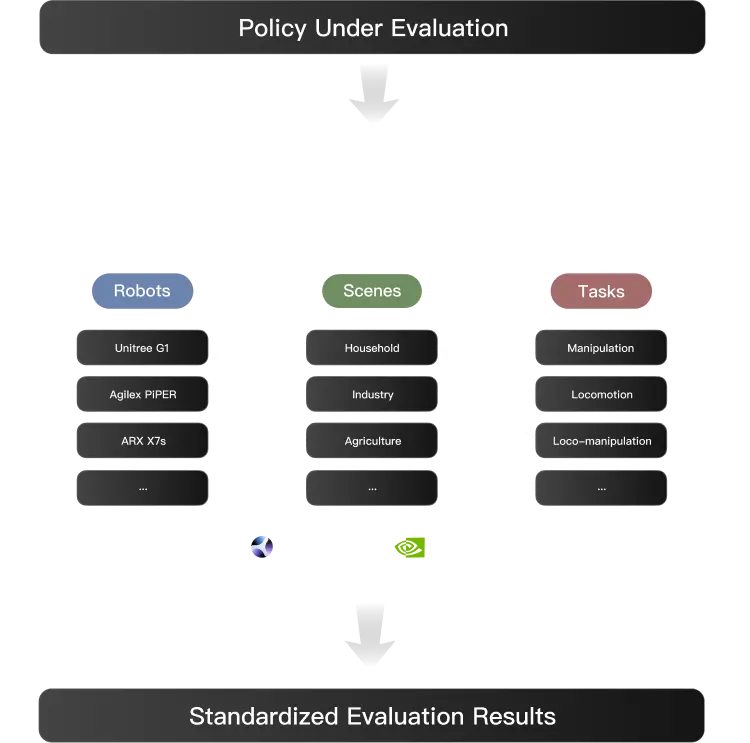
Isaac Lab – Arena cleanly decouples tasks, robots, and scenes, enabling systematic recombination and evaluation of generalization
across embodiments and environments.
Through this ongoing collaboration, Lightwheel and NVIDIA are jointly establishing a scalable, open foundation for embodied AI evaluation—one that moves beyond academic benchmarks toward real-world relevance.
Lightwheel BenchHub: A Framework to Host Large-Scale Manipulation Based Benchmarks



Lightwheel BenchHub sits above Isaac Lab–Arena as a benchmark hosting and execution layer
BenchHub integrates:
- Benchmark task definitions
- Simulation assets and scene configurations
- Policy execution and rollout orchestration
- Evaluation pipelines and metrics
By decoupling benchmark infrastructure from individual task suites, BenchHub allows multiple benchmarks to be developed, extended, and compared over time on a shared, stable foundation.
The framework supports high-fidelity simulation with built-in domain randomization and scales across diverse embodiments, including single-arm manipulation, mobile manipulation, and full loco-manipulation systems.
To ensure evaluation validity, BenchHub leverages teleoperation data and deterministic trajectory replay to calibrate task feasibility, episode horizons, and success criteria. Policy performance is evaluated exclusively through standardized rollouts, ensuring that benchmark results reflect realistic control and interaction constraints rather than artifacts of idealized or fragile simulation setups.
Open-Sourcing LW-RoboCasa-Tasks
and LW-LIBERO-Tasks
Examples of LW-RoboCasa-Tasks
Together, these benchmarks span:
- 268 tasks spanning atomic skills to long-horizon composites, including RoboCasa atomic kitchen primitives (e.g., opening/closing drawers and doors, and navigation between fixtures) and composite multi-step tasks (e.g., washing dishes, setting the table, cooking/reheating) registered as Gymnasium environments. LIBERO tasks further stress multi-object manipulation, spatial reasoning, and multi-step operations across tabletop and room scenes.
- USD-Based Scene Suites: RoboCasa includes 100 USD-based kitchen scenes defined by 10 layouts × 10 styles, with physics-accurate simulation and fully interactive fixtures (cabinets, drawers, appliances). LIBERO adds 4 tabletop scene families, extending tabletop manipulation coverage. Scenes are delivered via remote loading with local caching, enabling consistent, scalable parallel evaluation.
- 8 robot embodiment families comprising 28 concrete robot variants, including Unitree G1, PandaOmron, Panda, Double Panda, LeRobot SO100/101, Agilex Piper, Double Piper, and ARX-X7s—spanning single-arm manipulators, mobile dual-arm systems, and bipedal loco-manipulation platforms.
Each task–robot configuration is evaluated over 50 standardized episodes, yielding 20,000+ controlled evaluation episodes that enable statistically grounded comparison across tasks, scenes, and robot embodiments.
Designed for consistency and scale, these task suites support distribution-level evaluation of embodied policies, exposing robustness and generalization beyond isolated, point-wise success.